Welcome !
to Kaykobad Reza Blog
Currently pursuing Ph.D in Multimodal Machine Learning and Computer Vision
About Me
Featured Post
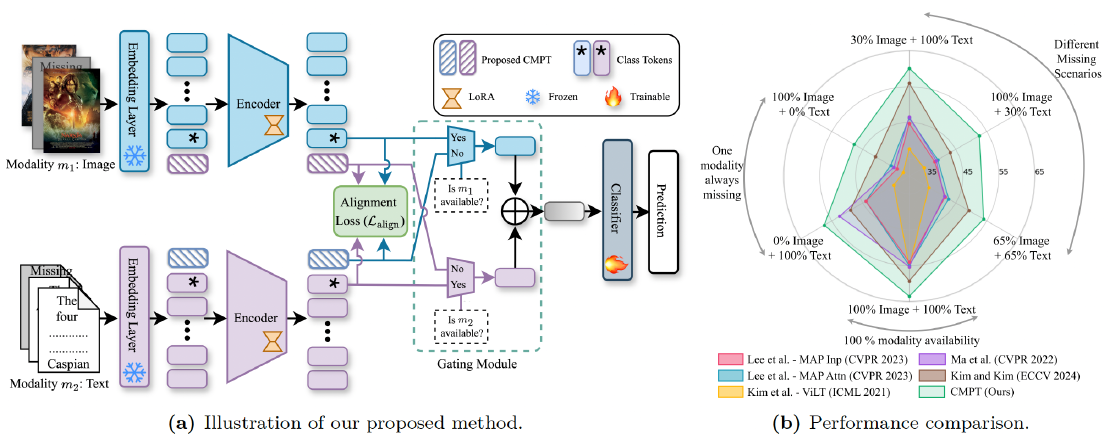
Robust Multimodal Learning via Cross-Modal Proxy Tokens
Imagine an AI designed to understand the world through multiple senses—like sight and hearing. It can identify a cat by both its picture (vision) and its “meow” (audio).
Read more
Recent Post
Robust Multimodal Learning via Cross-Modal Proxy Tokens
Imagine an AI designed to understand the world through multiple senses—like sight and hearing. It can identify a cat by both its picture (vision) and its “meow” (audio).
Read more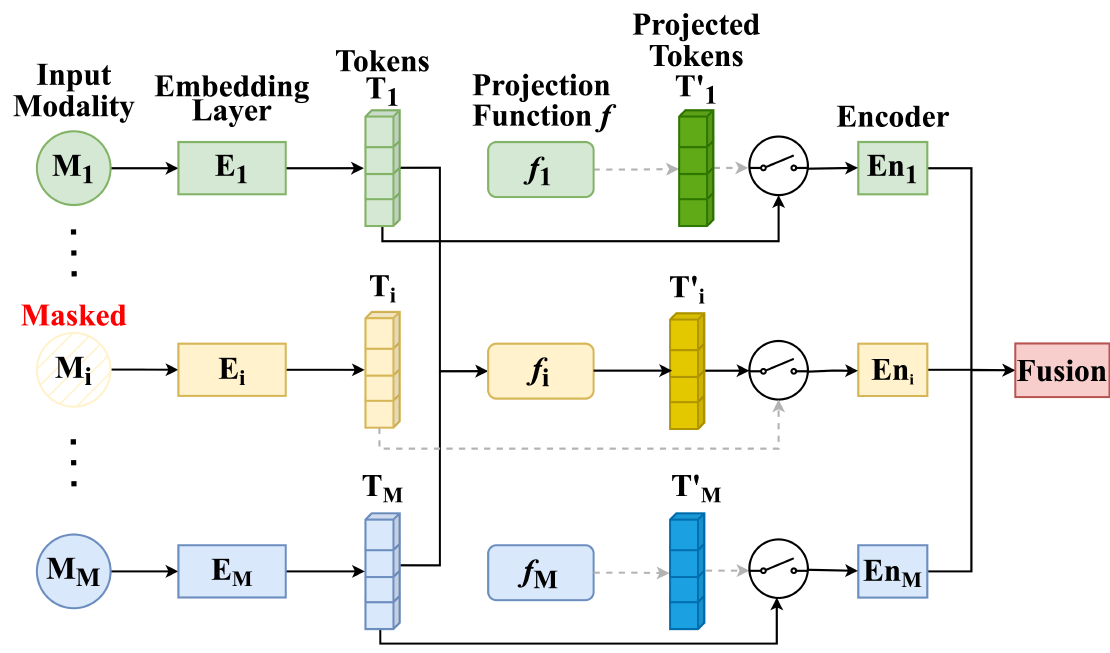
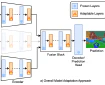
MMP: Towards Robust Multi-Modal Learning with Masked Modality Projection
In real-world applications, input modalities might be missing due to factors like sensor malfunctions or data constraints. Our recent paper addresses this challenge with a method called …
Read more
Basin-wide groundwater level forecasting with Transfer Learning and LSTM
Groundwater is the lifeline of millions, but predicting its levels—especially over large areas—is very difficult. Traditional physically based models demand immense data and computational …
Read more
Increase Your Research Visibility: How to Ensure Your Research Gets the Attention It Deserves
You have spent a few months, maybe even years, into your research. The late-night experiments, the endless cycle of writing and revising, the nail-biting wait for peer review.
Read more
From Paper to Podium: How to Convert a LaTeX Project to a Presentation Using LLMs
Imagine this: you’ve just wrapped up a semester-long research project. Your LaTeX paper is polished, perfected, and submitted to a top-tier conference.
Read more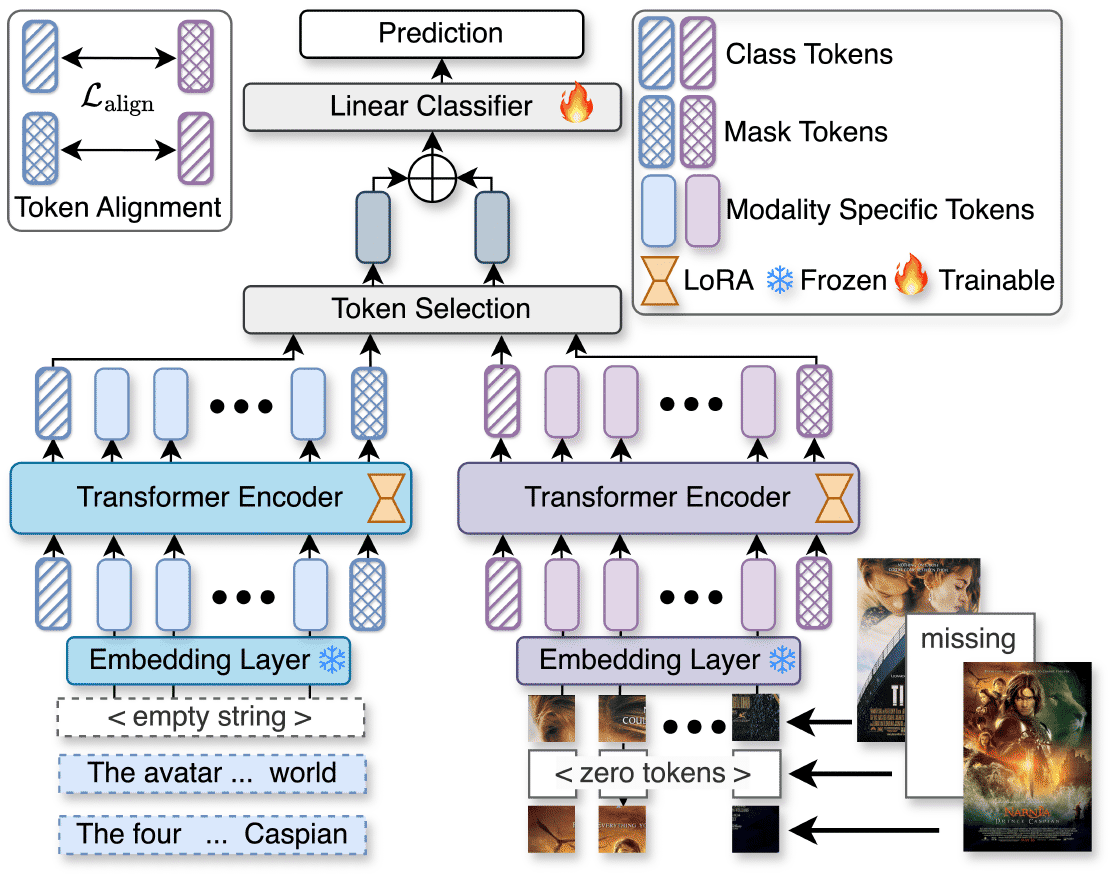
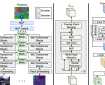
U2A: Unified Unimodal Adaptation for Robust and Efficient Multimodal Learning
Imagine you are using an AI system that analyzes both images and text to classify food items. It works great—until suddenly, the text data is missing.
Read more