
MMSFormer: Multimodal Transformer for Material and Semantic Segmentation
Leveraging information across diverse modalities is known to enhance performance on multimodal segmentation tasks. However, effectively fusing information from different modalities remains challenging due to the unique characteristics of each modality.
Summary of the Paper
In this paper, we propose a novel fusion strategy that can effectively fuse information from different modality combinations. We also propose a new model named Multi-Modal Segmentation TransFormer (MMSFormer) that incorporates the proposed fusion strategy to perform multimodal material and semantic segmentation tasks. MMSFormer outperforms current state-of-the-art models on three different datasets. As we begin with only one input modality, performance improves progressively as additional modalities are incorporated, showcasing the effectiveness of the fusion block in combining useful information from diverse input modalities. Ablation studies show that different modules in the fusion block are crucial for overall model performance. Furthermore, our ablation studies also highlight the capacity of different input modalities to improve performance in the identification of different types of materials.
Our Contribution
In this paper, we propose a novel fusion block that can fuse information from diverse combination of modalities. We also propose a new model for multimodal material and semantic segmentation tasks that we call MMSFormer. Our model uses transformer based encoders to capture hierarchical features from different modalities, fuse the extracted features with our novel fusion block and utilizes MLP decoder to perform multimodal material and semantic segmentation. In particular, our proposed fusion block uses parallel convolutions to capture multi-scale features, channel attention to re-calibrate features along the channel dimension and linear layer to combine information across multiple modalities. Such a design provides a simple fusion block that can handle an arbitrary number of input modalities and combine information effectively from different modality combinations.
The main contributions can be summarized as follows:
- We propose a new multimodal segmentation model called MMSFormer. The model incorporates a novel fusion block that can fuse information from arbitrary (heterogeneous) combinations of modalities.
- Our model achieves new state-of-the-art performance on three different datasets. Furthermore, our method achieves better performance for all modality combinations compared to the current leading models.
- A series of ablation studies show that each module on the fusion block has an important contribution towards the overall model performance and each input modality assists in identifying specific material classes.
Comparison with Baseline Models
The following table shows the performance comparison on FMB (left) and MCubeS (right) datasets. Here A, D, and N represent angle of linear polarization (AoLP), degree of linear polarization (DoLP), and near-infrared (NIR) respectively.
 and MCubeS (right) datasets.")
The figure below shows the visualization of predictions on MCubeS and PST900 datasets. Figure 2a shows RGB and all modalities (RGB-A-D-N) prediction from CMNeXt and our model on MCubeS dataset. For brevity, we only show the RGB image and ground truth material segmentation maps along with the predictions. Figure 2b shows predictions from RTFNet, FDCNet and our model for RGB-thermal input modalities on PST900 dataset. Our model shows better predictions on both of the datasets.

The following table shows the per-class % IoU comparison on MCubeS dataset. Our proposed MMSFormer model shows better performance in detecting most of the classes compared to the current state-of-the-art models. ∗ indicates that the code and pretrained model from the authors were used to generate the results.

The following table shows the per-class % IoU comparison on FMB dataset for both RGB only and RGB-infrared modalities. We show the comparison for 8 classes (out of 14) that are published. T-Lamp and T-Sign stand for Traffic Lamp and Traffic Sign respectively. Our model outperforms all the methods for all the classes except for the truck class.

The following table shows the performance comparison on PST900 dataset. We show per-class % IoU as well as % mIoU for all the classes.

Effect of Adding Different Modalities
The following table shows the per class % IoU comparison on Multimodal Material Segmentation (MCubeS) dataset for different modality combinations. As we add modalities incrementally, overall performance increases gradually. This table also shows that specific modality combinations assist in identifying specific types of materials better.
 dataset for different modality combinations.")
The figure below shows the visualization of predicted segmentation maps for different modality combinations on MCubeS and FMB datasets. Both figures show that prediction accuracy increases as we incrementally add new modalities. They also illustrate the fusion block’s ability to effectively combine information from different modality combinations.

The paper also contains ablation studies that explore the contribution of different modalities to detect different materials as well as the importance of each module in the fusion block.
More Details About the Paper
- Date First Available on IEEE OJSP: 16 April 2024
- Date First Available on arXiv: 7 September 2023
- Accepted By: IEEE Open Journal of Signal Processing
- Paper Link: IEEE OJSP | arXiv
- Project Webpage: Computational Sensing and Information Processing Lab, UCR
- Code and Pretrained Models: GitHub
- Authors: Md Kaykobad Reza , Ashley Prater-Bennette , and M. Salman Asif
Related Posts
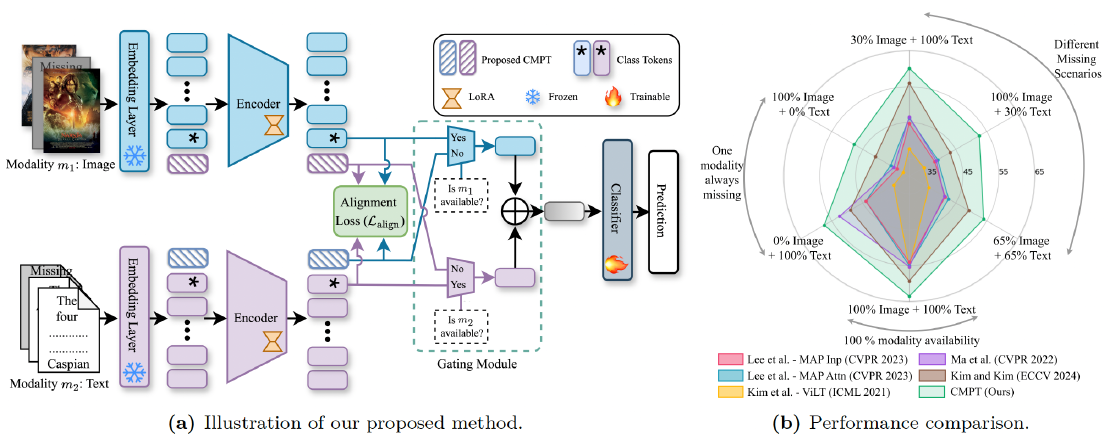
Robust Multimodal Learning via Cross-Modal Proxy Tokens
Imagine an AI designed to understand the world through multiple senses—like sight and hearing. It can identify a cat by both its picture (vision) and its “meow” (audio).
Read more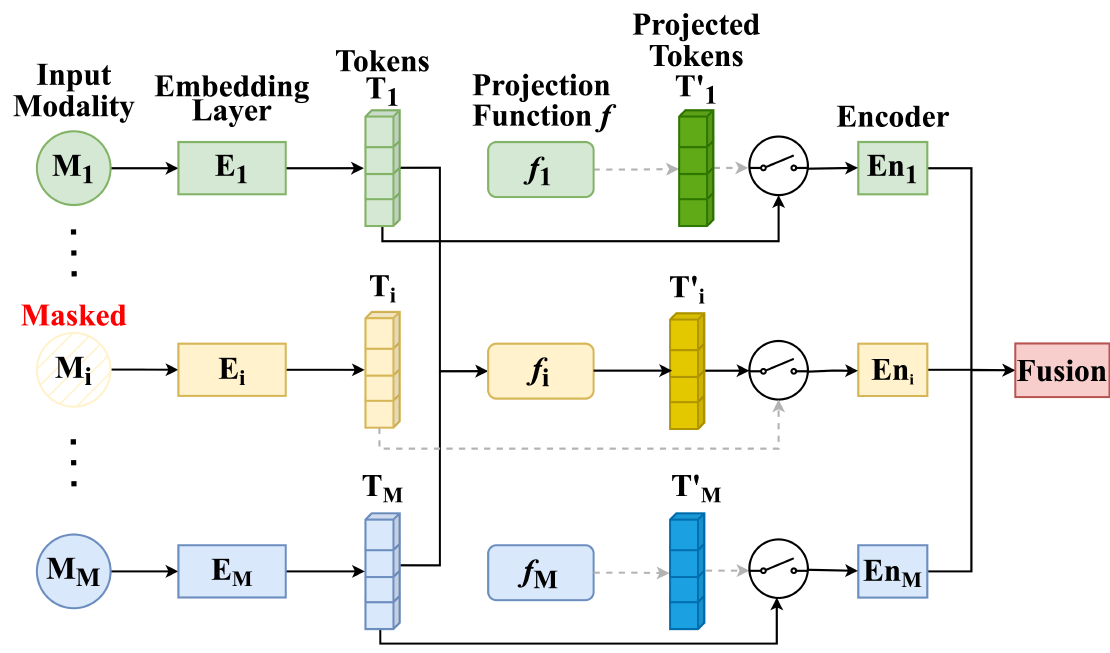
MMP: Towards Robust Multi-Modal Learning with Masked Modality Projection
In real-world applications, input modalities might be missing due to factors like sensor malfunctions or data constraints. Our recent paper addresses this challenge with a method called …
Read more
Basin-wide groundwater level forecasting with Transfer Learning and LSTM
Groundwater is the lifeline of millions, but predicting its levels—especially over large areas—is very difficult. Traditional physically based models demand immense data and computational …
Read more