Robust Multimodal Learning with Missing Modalities via Parameter-Efficient Adaptation
Missing modalities at test time can cause significant degradation in the performance of multimodal systems. In this paper, we presented a simple and parameter-efficient adaptation method for robust multimodal learning with missing modalities. We demonstrated that simple linear operations can efficiently transform a single pretrained multimodal network and achieve performance comparable to multiple (independent) dedicated networks trained for different modality combinations.
Summary of the Paper
Multimodal learning seeks to utilize data from multiple sources to improve the overall performance of downstream tasks. It is desirable for redundancies in the data to make multimodal systems robust to missing or corrupted observations in some correlated modalities. However, we observe that the performance of several existing multimodal networks significantly deteriorates if one or multiple modalities are absent at test time. To enable robustness to missing modalities, we propose simple and parameter-efficient adaptation procedures for pretrained multimodal networks. In particular, we exploit low-rank adaptation and modulation of intermediate features to compensate for the missing modalities. We demonstrate that such adaptation can partially bridge performance drop due to missing modalities and outperform independent, dedicated networks trained for the available modality combinations in some cases. The proposed adaptation requires extremely small number of parameters (e.g., fewer than 0.7% of the total parameters in most experiments). We conduct a series of experiments to highlight the robustness of our proposed method using diverse datasets for RGB-thermal and RGB-Depth semantic segmentation, multimodal material segmentation, and multimodal sentiment analysis tasks. Our proposed method demonstrates versatility across various tasks and datasets, and outperforms existing methods for robust multimodal learning with missing modalities.
Our Contribution
In this paper, we propose a parameter-efficient approach to build a multimodal network that can adapt to arbitrary combinations of input modalities. Our main objective is to modify the network in a controllable manner as a function of available modalities.
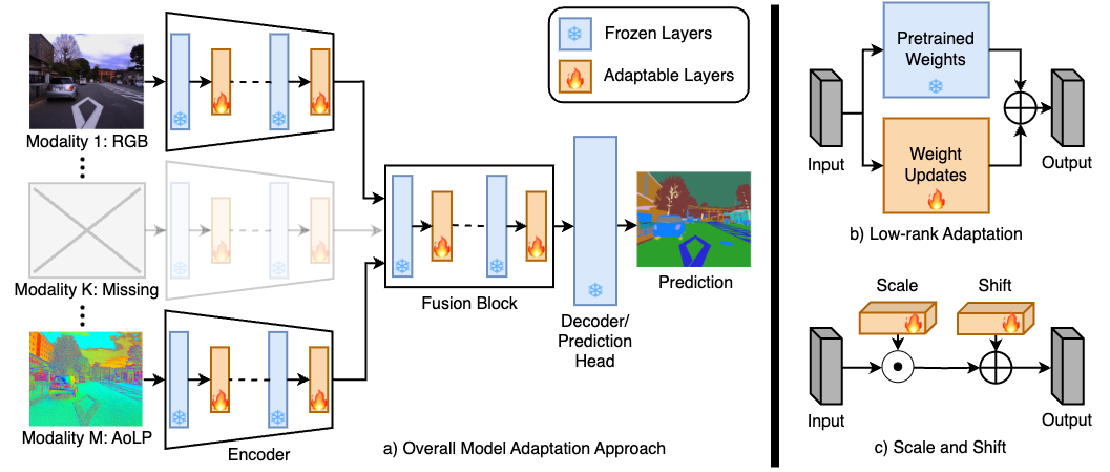
The header figure illustrates our proposed method, where a given multimodal network can be adapted to arbitrary modality combinations by transforming the intermediate features at different layers. To achieve parameter-efficient adaptation, we propose to use simple linear transformations such as scaling, shifting, or low-rank increments of features. Our method does not require retraining the entire model or any specialized training strategy. The adapted networks provide significant performance improvement over the multimodal networks trained with all modalities and tested with missing modalities. Performance of the adapted models is also comparable or better than the models that are exclusively trained for each input modality combination. We present a series of experiments to evaluate our method and compare with existing methods for robust MML. We tested different parameter-efficient adaptation strategies and found scaling and shifting features provides overall best performance with less than 0.7% of the total parameters.
The main contributions can be summarized as follows:
- We propose parameter-efficient adaptation for multimodal learning that is robust to missing modalities. The adapted model can easily switch to different network states based on the available modalities with minimal latency, computational, or memory overhead.
- The adapted networks provide notably improved performance with missing modalities when compared to models trained with all modalities and is comparable to or better than the networks trained for specific modality combinations.
- Our approach is versatile and adaptable to a wide range of multimodal tasks and models. Detailed evaluations on diverse datasets and tasks show that our approach outperforms existing baseline methods and robust models designed for specific tasks and datasets.
Experiments on Multimodal Segmentation
Performance of Pretrained, Dedicated, and Adapted networks with missing modalities is shown on the following table. CMNeXt is the base model for multimodal semantic segmentation for MFNet and NYUDv2 datasets and multimodal material segmentation for MCubeS dataset. HHA-encoded images were used instead of raw depth maps. Bold letters represent best results.

Visualization of predicted segmentation maps for pretrained and adapted models on MFNet and NYUDv2 datasets for multimodal semantic segmentation and MCubeS dataset for multimodal material segmentation is shown on the following figure. Only RGB images are shown from MCubeS dataset for brevity. CMNeXt column shows the predictions when all the modalities are available. Segmentation quality improves significantly after model adaptation for all the input modality combinations. A, D and N stand for angle of linear polarization, degree of linear polarization and near-infrared respectively.

Comparison with Baseline Models and Methods
The following table shows the performance comparison with existing robust methods for MFNet dataset. RGB and Thermal columns report performance when only RGB and Thermal are available. Average column reports average performance when one of the two modalities gets missing. ‘-’ indicates that results for those cells are not published. Mean accuracy (mAcc) and % mean intersection over union (mIoU) are shown for all the experiments.

The following table shows the performance comparison with existing robust methods for NYUDv2 dataset. RGB and Depth columns report performance when only RGB and Depth are available. Average column indicates average performance when one of the two modalities gets missing. * indicates that available codes and pretrained models from the authors were used to generate the results. Other results are from the corresponding papers.

The following table shows the performance comparison (% mIoU) of different parameter-efficient adaptation techniques for MFNet, NYUDv2, and MCubeS datasets. Each column reports mIoU of the Adapted model with the corresponding modalities, and Avg indicates average performance. A and D denote Angle and Degree of Linear Polarization.

Experiments for Multimodal Sentiment Analysis
Following table shows the performance of Pretrained and Adapted models for multimodal sentiment analysis with CMU-MOSI and CMU-MOSEI datasets. Multimodal Transformer (MulT) as the base model. A, V and T denote audio, video, and text, respectively. ↑ means higher is better and ↓ means lower is better. The Adapted model outperforms the Pretrained model with missing modalities.

More Details About the Paper
- Date First Available on IEEE TPAMI: 10 October 2024
- Date First Available on arXiv: 6 October 2023
- Accepted By: IEEE Transactions on Pattern Analysis and Machine Intelligence
- Paper Link: IEEE TPAMI | arXiv
- Project Webpage: Computational Sensing and Information Processing Lab, UCR
- Authors: Md Kaykobad Reza , Ashley Prater-Bennette , and M. Salman Asif
Related Posts

MMSFormer: Multimodal Transformer for Material and Semantic Segmentation
Leveraging information across diverse modalities is known to enhance performance on multimodal segmentation tasks. However, effectively fusing information from different modalities remains …
Read more
Robust Multimodal Learning via Cross-Modal Proxy Tokens
Imagine an AI designed to understand the world through multiple senses—like sight and hearing. It can identify a cat by both its picture (vision) and its “meow” (audio).
Read more
MMP: Towards Robust Multi-Modal Learning with Masked Modality Projection
In real-world applications, input modalities might be missing due to factors like sensor malfunctions or data constraints. Our recent paper addresses this challenge with a method called …
Read more