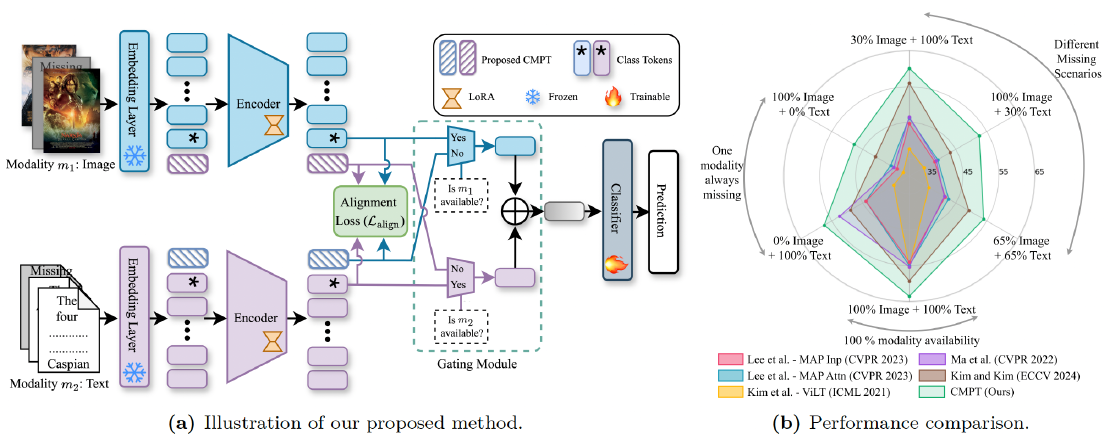
Robust Multimodal Learning via Cross-Modal Proxy Tokens
Imagine an AI designed to understand the world through multiple senses—like sight and hearing. It can identify a cat by both its picture (vision) and its “meow” (audio). But what happens if the microphone fails and there is no audio? The AI suddenly becomes half-blind, and its performance plummets.
In an ideal world, we always have complete data—text, images, audio, video—everything in sync and perfectly aligned. But the real world is messy. Data can be lost or unavailable due to sensor failures or even privacy concerns. This “missing modality” problem is a huge challenge in artificial intelligence. Multimodal models , which are AIs that process different types of data, often stumble when one of their data streams goes missing.
🧠 The Problem: When Multimodal AI Loses a Modality
Modern multimodal models (think AI that can process both images and text, or video and audio) usually expect everything to be present during inference. But what happens if a modality is missing—like if a movie poster is there but the synopsis is not? Unfortunately, most existing models just fall apart .
So how do we make sure AI systems still perform well even when some of that data goes missing?
🎯 Our Solution: Cross-Modal Proxy Tokens (CMPTs)
Our research introduces Cross-Modal Proxy Tokens (CMPTs)—a simple yet effective solution that enhances robustness. CMPTs are powerful, learned tokens that act as a stand-in for missing data. Instead of generating the missing modality from scratch or using complex auxiliary networks, CMPTs learn to approximate what’s missing by attending only to the tokens of the modality that is available.
Imagine a model that only sees an image of a food item but can still “guess” the type of dish with high accuracy, as if it had also read the recipe. That’s the power of CMPTs in action.
📊 Key Highlights
So, does it work? Absolutely. We tested our CMPT framework on five different multimodal datasets across various tasks, and the results speak for themselves.
- ✅ Outperforming the Competition: In scenarios with missing modalities, our method consistently outperformed state-of-the-art approaches, including 12 recent baseline methods on four different datasets.
- ✅ No Compromise on Quality: A common fear is that making a model robust will hurt its performance when all data is available. Our method shows no such compromise, achieving competitive and often superior results in complete-data settings.
- ✅ Ready for the Real World: Real-world data is unpredictable. We showed that our model generalizes effectively even when the rate of missing data changes during testing—a critical feature for practical applications.
- ✅ Benefits Across the Board: We dug deeper and found the performance boost isn’t just an average improvement. CMPTs help the model perform better across nearly all classes, leading to a strong overall performance improvement.
Overall, our CMPT-based framework achieves state-of-the-art performance, demonstrating superior generalization and effectiveness compared to existing methods across a wide variety of datasets and tasks.
Why This Matters and What’s Next
Our work on Cross-Modal Proxy Tokens offers a flexible, efficient, and powerful solution for a persistent problem in AI. By making multimodal systems more robust, we can build more reliable applications for real-world applications.
While our method marks a significant step forward, there’s still room for improvement, especially in extreme cases where data is severely limited or for classes that are heavily dependent on a single modality. As part of our ongoing work, we are actively exploring how to extend this framework to handle more than two modalities—a natural next step for this research.
Eager to learn more? Dive into the full details of our research by reading the paper on arXiv !
More Details About the Paper
- Accepted By: Transactions on Machine Learning Research (TMLR)
- Date First Available on arXiv: 29 January 2025
- Date of Acceptance: 21 October 2025
- Date First Available on TMLR: 30 October 2025
- Paper Link: TMLR | arXiv
- Authors: Md Kaykobad Reza , Ameya Patil , Mashhour Solh , and M. Salman Asif
- Project Webpage: Computational Sensing and Information Processing Lab, UCR
- Code and Pretrained Models: GitHub
Related Posts
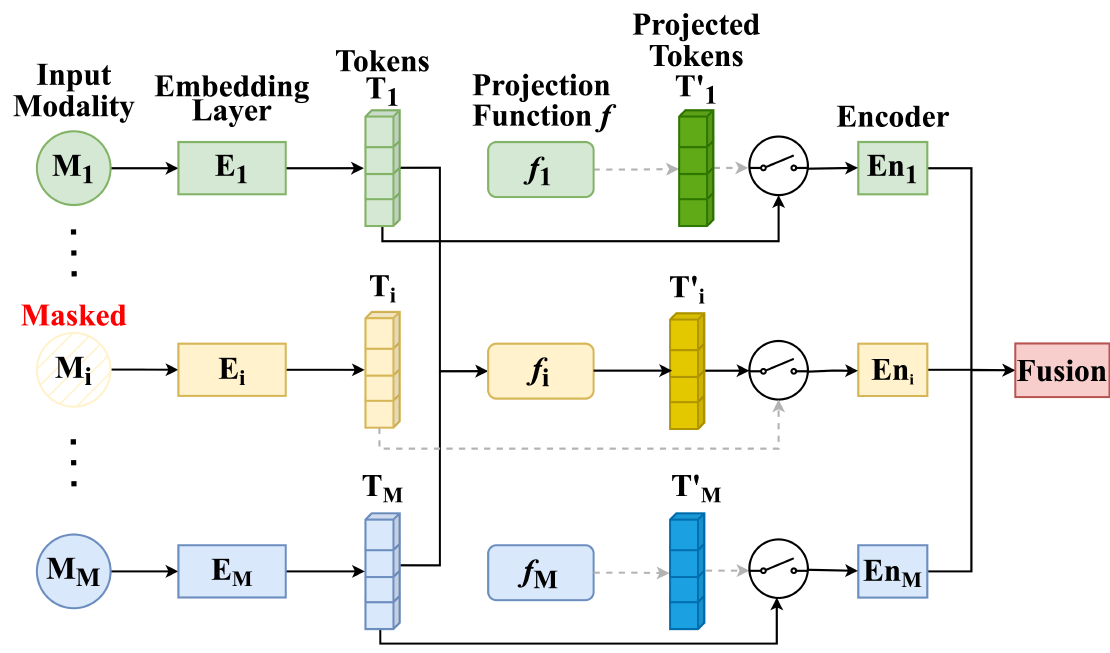
MMP: Towards Robust Multi-Modal Learning with Masked Modality Projection
In real-world applications, input modalities might be missing due to factors like sensor malfunctions or data constraints. Our recent paper addresses this challenge with a method called …
Read more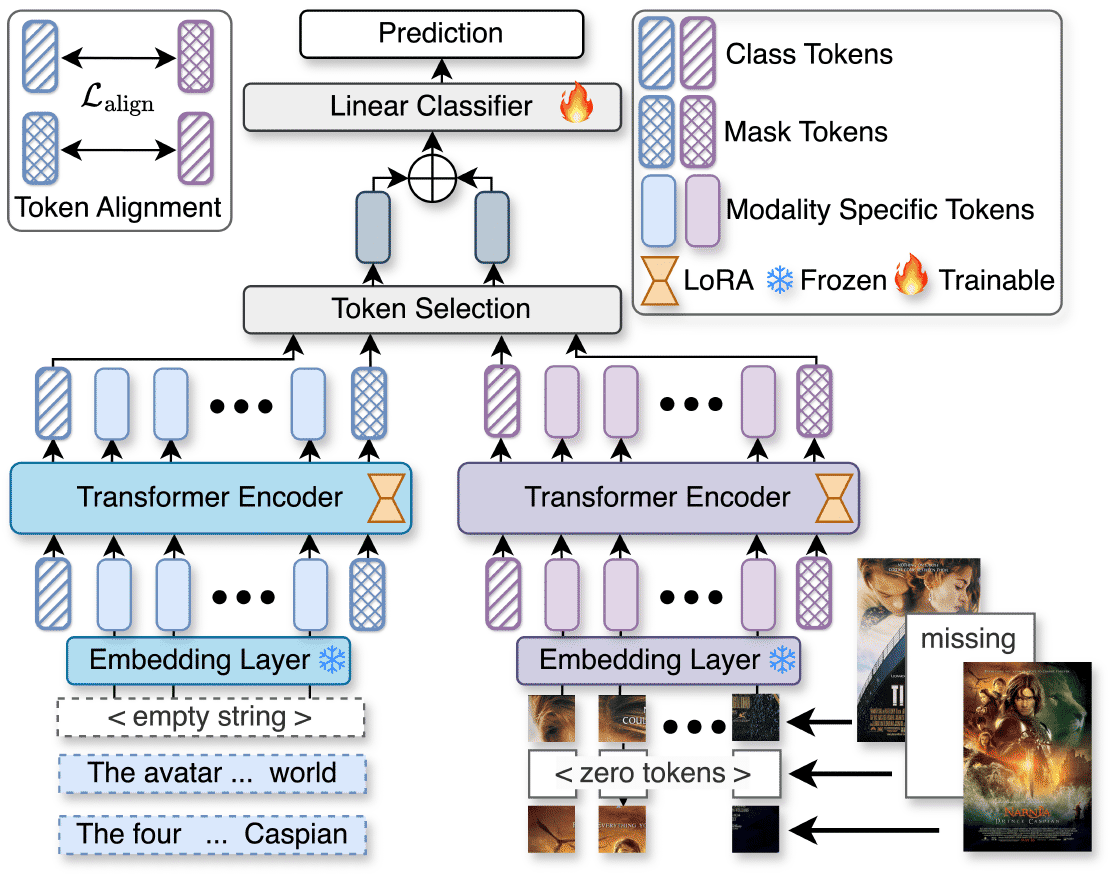
U2A: Unified Unimodal Adaptation for Robust and Efficient Multimodal Learning
Imagine you are using an AI system that analyzes both images and text to classify food items. It works great—until suddenly, the text data is missing.
Read more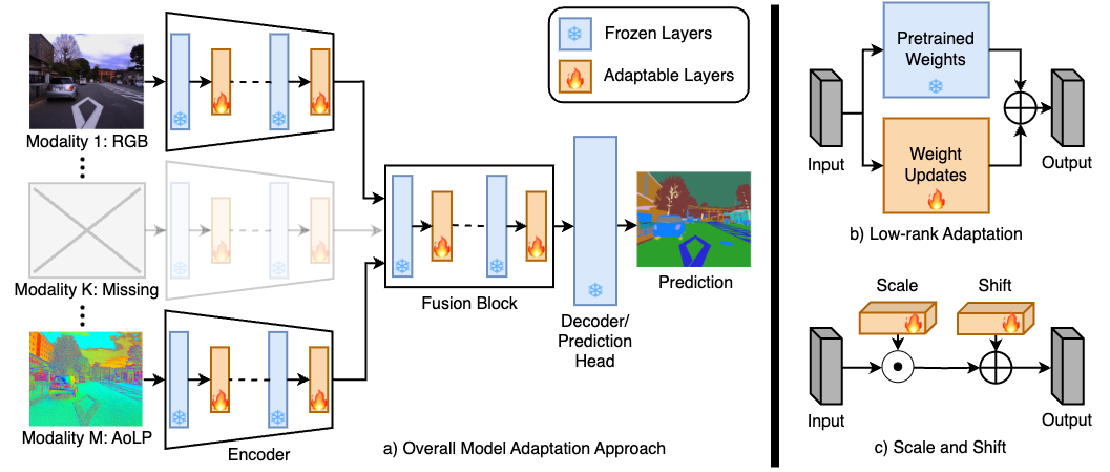
Robust Multimodal Learning with Missing Modalities via Parameter-Efficient Adaptation
Missing modalities at test time can cause significant degradation in the performance of multimodal systems. In this paper, we presented a simple and parameter-efficient adaptation method for …
Read more