
Basin-wide groundwater level forecasting with Transfer Learning and LSTM
Groundwater is the lifeline of millions, but predicting its levels—especially over large areas—is very difficult. Traditional physically based models demand immense data and computational effort. On the other hand, modern deep learning (DL) methods often require training individual models for each well—making basin-scale applications costly and impractical.
What if one AI model could predict groundwater levels across an entire basin—faster, cheaper, and just as accurately as training dozens of models?
What is the Problem?
With growing populations, expanding industries, and the unpredictable effects of climate change, our planet’s freshwater resources are under immense pressure. A significant portion of this freshwater is hidden beneath our feet as groundwater. It is a critical resource for agriculture, industry, and daily life. However, this vital resource is facing threats of depletion and pollution worldwide.
To manage this resource sustainably, water managers need to know how much groundwater is available, not just today, but in the near future. This is where forecasting comes in.
The Challenge: The Scaling Problem in Groundwater Forecasting
Predicting groundwater levels (GWL) is incredibly complex. The way water moves underground is hidden and varies greatly from one place to another. While traditional physical models can simulate these systems, they are often complex and require vast amounts of data that can be difficult to obtain.
In recent years, deep learning (DL) models, especially the Long Short-Term Memory (LSTM) network , have shown remarkable success in forecasting GWL at specific locations. LSTMs are a type of artificial intelligence particularly good at learning from time-series data, like monthly rainfall and groundwater records.
However, there is a catch. To achieve high accuracy, these powerful DL models typically need to be built and trained from scratch for each individual observation well. Imagine doing this for a region with dozens or hundreds of wells! The process is time-consuming (taking days or even weeks), computationally expensive, and requires significant expertise. This has been a major barrier to applying these advanced models on a large, basin-wide scale.
Our Solution: A Smarter, Faster Approach with Transfer Learning
What if we could train just one “master” model and then quickly adapt it for any location within a region? This is the core idea behind our new study, published in the Hydrological Sciences Journal. We introduce a novel approach that combines the power of LSTM with a technique called Transfer Learning (TL) .
Here’s how our Transfer Learning-aided LSTM (TL-LSTM) model works:
- Train a “Pre-trained” Model: We first created a single, highly accurate LSTM model by training it on the average groundwater level data from across the entire Kumamoto Groundwater Basin in Japan . This “pre-trained” model learns the general patterns and dynamics of the whole groundwater system.
- Transfer the Knowledge: Instead of building a new model from zero for each well, we take our pre-trained model and transfer its learned knowledge.
- Fine-Tune for Specifics: We then “fine-tune” only the last few layers of the model using the data from a specific well. This quickly adapts the general knowledge to the unique characteristics of that particular location. The initial layers, which hold the core knowledge, remain “frozen.”
This process is like a skilled chef training an apprentice. The chef (our pre-trained model) imparts years of general culinary knowledge. The apprentice (the new model) then only needs a small amount of specific training to master a new dish (predicting GWL at a new well).
What We Found: Key Insights from Our Study
Our research shows that this new TL-LSTM approach is a game-changer for hydrological forecasting.
- High Accuracy: The TL-LSTM models achieved forecasting accuracy that was nearly identical to the highly-tuned, individually trained (IT-LSTM) models. For one-month-ahead forecasting, the average Nash-Sutcliffe Efficiency (NSE), a common performance metric, was 0.92 for our old models and 0.91 for the new TL-LSTM models.
- Massive Time Savings: The most significant advantage is the incredible gain in efficiency. Developing models for all seven observation wells in our study area required only a fraction of the time and computational power compared to the traditional one-by-one method. We reduced the model development timeline from potentially weeks to just minutes for each new location.
- Superior Performance: Our study also confirmed that LSTM-based models, whether individually trained or using our new transfer learning approach, are significantly more accurate than conventional machine learning models like Support Vector Regression (SVR) and Random Forest (RF) .
Challenges and the Road Ahead
While our TL-LSTM framework is a powerful tool for scaling up groundwater forecasting, we also identified areas for future improvement.
- The model’s accuracy was slightly lower for one well located in a hilly area with very distinct geological and hydrological features. This suggests that for very large and diverse basins, a single pre-trained model might not be enough.
- Future research could explore developing a library of pre-trained models for different types of sub-regions (e.g., mountainous, coastal plains).
- We can also investigate more advanced transfer learning strategies and integrate data from multiple sources, like satellite measurements and land use maps, to make the models even more robust.
Concluding Thoughts
By integrating transfer learning, we are not just making a better model; we are creating a smarter and more efficient workflow for water management. This leap in efficiency means that powerful, data-driven forecasting is no longer a niche academic exercise but a practical tool that can be deployed at scale. It is a crucial step forward in our efforts to sustainably manage groundwater for generations to come.
More Details About the Paper
- Accepted By: Hydrological Sciences Journal (HSJ)
- Paper Link: HSJ
- Date of Acceptance: 10 June 2024
- Date First Available on HSJ: 09 July 2025
- Authors: ATM Sakiur Rahman , Shahriar M Sakib , Md Kaykobad Reza , Amiya Basak, Khandaker Nusaiba Hafiz , Md Shazid Islam , Takahiro Hosono
Related Posts
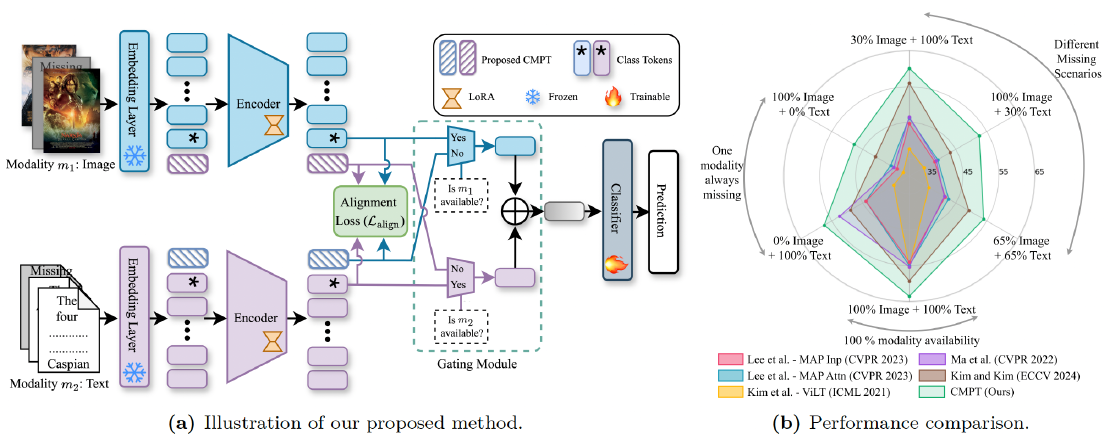
Robust Multimodal Learning via Cross-Modal Proxy Tokens
Imagine an AI designed to understand the world through multiple senses—like sight and hearing. It can identify a cat by both its picture (vision) and its “meow” (audio).
Read more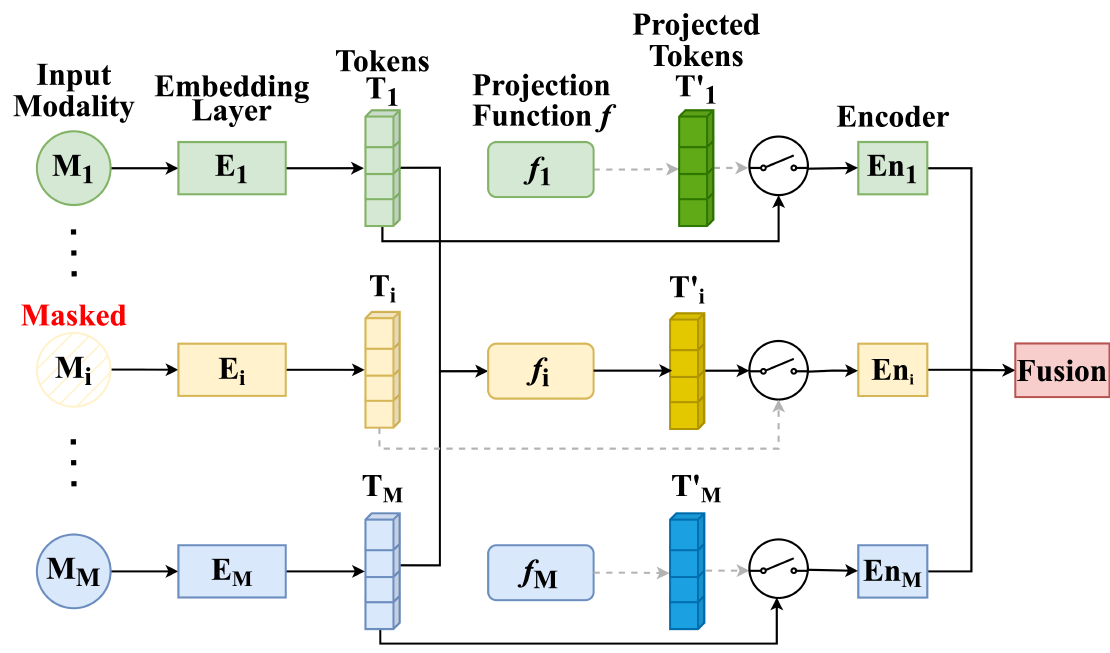
MMP: Towards Robust Multi-Modal Learning with Masked Modality Projection
In real-world applications, input modalities might be missing due to factors like sensor malfunctions or data constraints. Our recent paper addresses this challenge with a method called …
Read more
Increase Your Research Visibility: How to Ensure Your Research Gets the Attention It Deserves
You have spent a few months, maybe even years, into your research. The late-night experiments, the endless cycle of writing and revising, the nail-biting wait for peer review.
Read more