U2A: Unified Unimodal Adaptation for Robust and Efficient Multimodal Learning
Imagine you’re using an AI system that analyzes both images and text to classify food items. It works great—until suddenly, the text data is missing. The AI stumbles, accuracy drops, and the system struggles. This is not just a hypothetical scenario; missing modalities are a common challenge in real-world multimodal learning. So, can we build AI models that are both efficient and robust to missing modalities?
In our latest research, “U2A: Unified Unimodal Adaptation for Robust and Efficient Multimodal Learning,” we propose a simple yet powerful solution to this problem.
Why This Matters
Multimodal AI systems—those that learn from multiple data types like text, images, and audio—are increasingly essential. They power applications in healthcare, autonomous vehicles, and surveillance. But there’s a catch: real-world data is messy. Sensors fail, text descriptions get missing, or audio recordings become corrupted. Most existing models require expensive retraining or complex fusion techniques to handle these cases.
We set out to answer a crucial question: 💡 Can we make multimodal models robust to missing data while keeping them efficient and scalable?
Our Approach: Unified Unimodal Adaptation (U2A)
Instead of designing task-specific architectures, U2A takes a different approach:
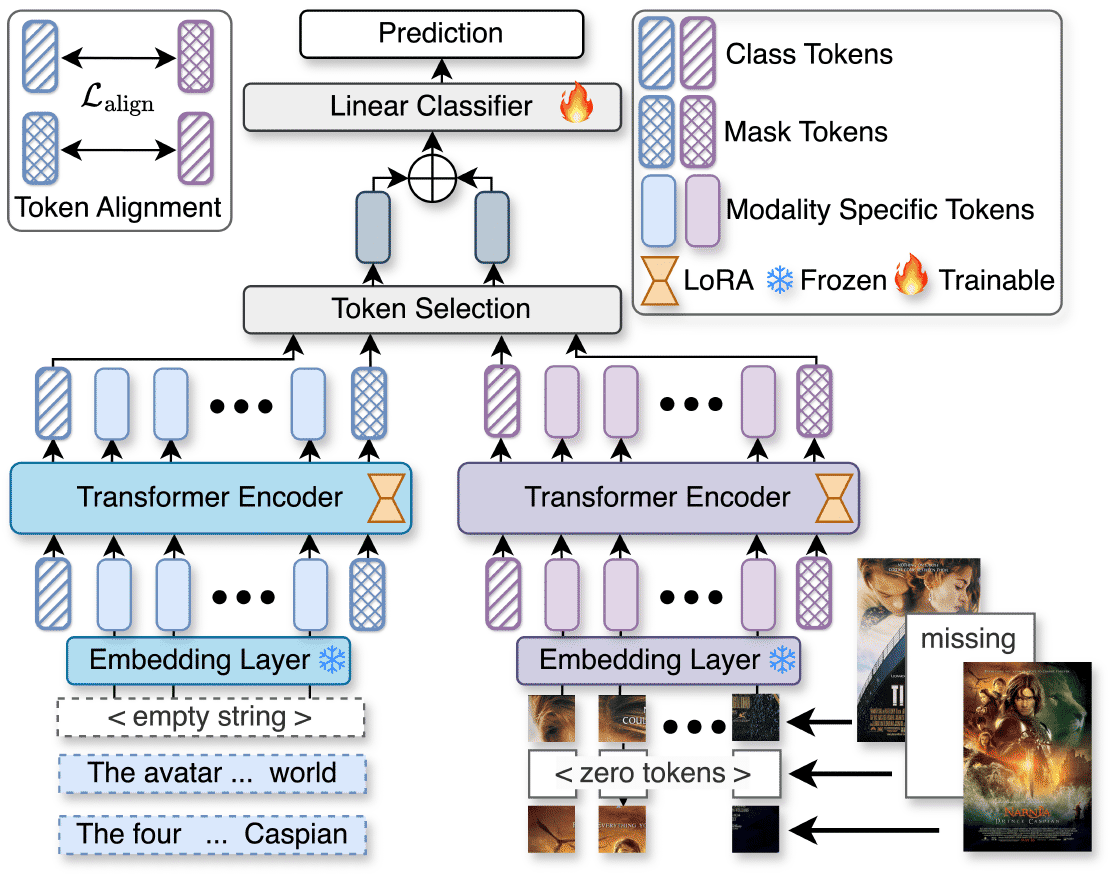
- ✅ Adapt Pretrained Unimodal Encoders: We fine-tune existing encoders (e.g., CLIP for images, BERT for text) using Low-Rank Adaptation (LoRA). This dramatically reduces trainable parameters while maintaining performance.
- ✅ Mask Tokens (MT): To handle missing modalities, we introduce a single learnable token per modality that estimates missing features using available modalities. Unlike complex generative models, this method is fast and lightweight.
- ✅ Robust & Efficient: U2A outperforms existing methods across multiple benchmarks while using fewer parameters. It works both when all modalities are present and when some are missing—a significant step toward real-world deployability.
Key Challenges in Multimodal Learning
Before diving into the insights, let’s talk about why this problem is hard.
- 🔹 Data Imbalance: Some modalities contain more information than others, making fusion tricky.
- 🔹 Computational Overhead: Traditional methods require learning complex relationships, increasing training costs.
- 🔹 Handling Missing Data: Most models assume complete data; handling missing modalities is often an afterthought.
What We Found
Through extensive experiments on five multimodal datasets (vision-language, audio-video, and more), we found that:
- 📌 U2A matches or beats state-of-the-art models while using significantly fewer learnable parameters.
- 📌 Mask Tokens effectively estimate missing modality features, preserving performance when inputs are incomplete.
- 📌 The impact of missing data varies—some classes are highly dependent on specific modalities, while others are more robust.
What’s Next? Open Questions & Future Directions
While U2A is a step forward, several open challenges remain:
- 🔎 Some classes suffer more when certain modalities are missing. Can we improve how models distribute reliance across modalities?
- 🔎 How do we ensure models generalize across unseen modalities? Future work could explore adaptive fusion strategies.
- 🔎 Can we develop a theoretical framework to quantify missing modality impact? Understanding this could lead to more resilient AI.
Final Thoughts
Multimodal AI is shaping the future, but it must be robust, efficient, and adaptable. Our work on U2A brings us closer to this goal, offering a scalable and effective solution to missing modalities.
We’d love to hear your thoughts! How do you think multimodal AI can evolve to handle real-world challenges better? Let’s discuss! 🚀
More Details About the Paper
- Paper Link: arXiv
- Date First Available on arXiv: 29 January 2025
- Authors: Md Kaykobad Reza , Niki Nezakati , Ameya Patil, Mashhour Solh, and M. Salman Asif
Related Posts
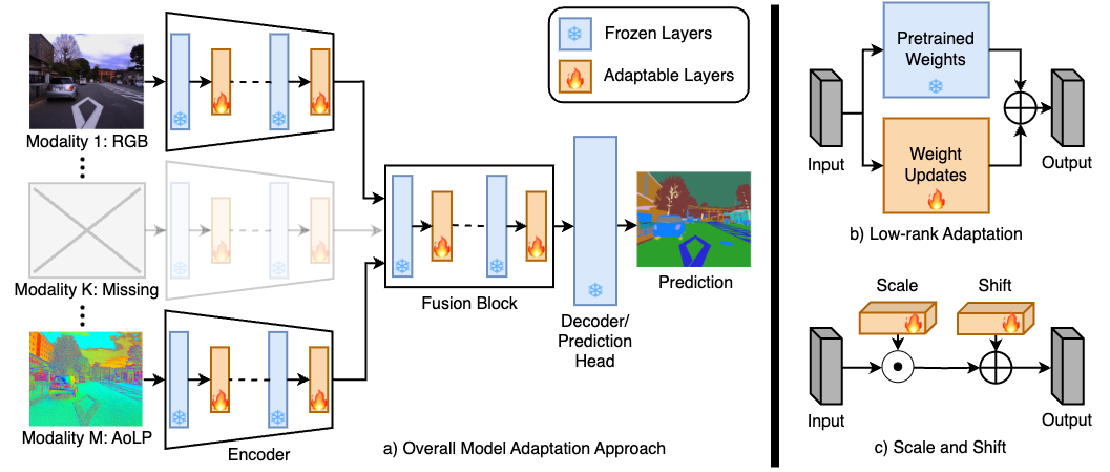
Robust Multimodal Learning with Missing Modalities via Parameter-Efficient Adaptation
Missing modalities at test time can cause significant degradation in the performance of multimodal systems. In this paper, we presented a simple and parameter-efficient adaptation method for …
Read more
MMP: Towards Robust Multi-Modal Learning with Masked Modality Projection
In real-world applications, input modalities might be missing due to factors like sensor malfunctions or data constraints. Our recent paper addresses this challenge with a method called …
Read more
MMSFormer: Multimodal Transformer for Material and Semantic Segmentation
Leveraging information across diverse modalities is known to enhance performance on multimodal segmentation tasks. However, effectively fusing information from different modalities remains …
Read more